
How to Eliminate Customer Data Duplication and Inconsistency for Good
June 24, 2025 / Bryan Reynolds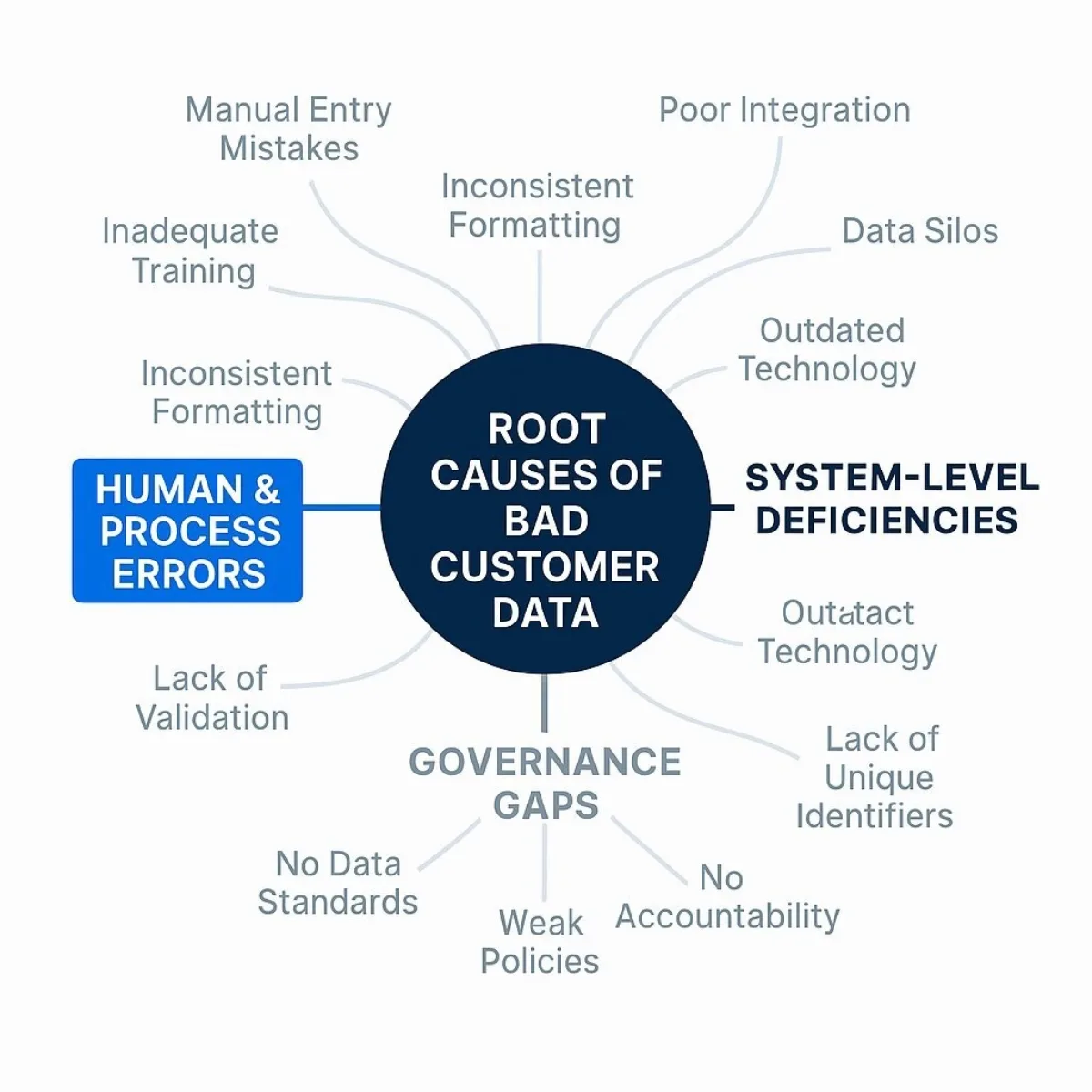
1. Executive Summary
The challenge of inconsistent and duplicated customer data is a pervasive issue that directly threatens the achievement of core business objectives. This report outlines the multifaceted nature of this problem, identifies its root causes, quantifies its detrimental impacts, and proposes a comprehensive strategy for remediation and long-term prevention. The primary causes of poor customer data quality can be broadly categorized into human and process-related errors, systemic deficiencies within data infrastructure, and critical gaps in organizational data governance.
The consequences of failing to address these issues are severe and far-reaching. They manifest as significant financial losses, with industry analyses highlighting that poor data quality can cost organizations millions annually. Beyond direct costs, businesses suffer from operational inefficiencies, compromised strategic decision-making due to unreliable analytics, and a marked erosion of customer trust stemming from flawed interactions.
Resolution demands a strategic, multi-pillar approach. This begins with a comprehensive assessment of the current data landscape to understand the extent and nature of the problem. It is followed by an intensive cleansing phase focused on correcting errors, standardizing formats, and eliminating duplications. Critically, the strategy must then shift to robust preventative measures to ensure data quality is maintained over time. This involves establishing a resilient data quality ecosystem , underpinned by Master Data Management (MDM) principles, a strong data governance framework, effective data stewardship, and the strategic deployment of appropriate technologies.
It is important to recognize that achieving and maintaining high data quality is not a singular project but a continuous cycle of improvement that necessitates cultural shifts alongside technical implementations. Implementing the recommendations outlined in this report will lead to tangible positive outcomes, including improved return on investment for data-related initiatives, enhanced customer satisfaction and loyalty, and the establishment of reliable business intelligence crucial for competitive advantage.
2. The Challenge of Inconsistent and Duplicated Customer Data
The integrity of customer data is paramount for any organization aiming to thrive in a data-driven environment. However, this integrity is frequently compromised by two insidious problems: data inconsistency and data duplication. Understanding these issues is the first step toward appreciating their profound impact on business performance.
2.1. Defining Data Inconsistency and Duplication in the Context of Customer Information
Data inconsistency refers to situations where the same piece of information about a customer is recorded in different, often conflicting, ways across various records or systems. For instance, a customer's address might be entered as "Street," "St.," or "Str." in different instances, creating ambiguity and hindering accurate data aggregation and analysis. Inconsistency can also manifest as conflicting attribute values for the same customer, such as different phone numbers or email addresses appearing in separate records that ostensibly refer to the same individual.
Data duplication is the unintentional existence of multiple records for the same customer entity within one or more databases. This means a single customer might appear two, three, or even more times, often with slight variations that make automatic detection difficult. It is useful to distinguish between two types of duplicates:
- Exact duplicates are identical copies of the same data record.
- Partial duplicates share some common fields but contain slight variations in others. For example, "Jon Smith" at "123 Main St" and "John Smith" also at "123 Main St" with the same date of birth could be a partial duplicate. These partial duplicates are often more challenging to identify and resolve than exact duplicates, yet they contribute significantly to data quality degradation. Their subtle nature means they can persist undetected for longer periods, continuously corrupting data analyses and operational processes.
2.2. The Pervasive Impact on Business Operations, Decision-Making, and Customer Experience
The presence of inconsistent and duplicated customer data is not merely an IT nuisance; it has tangible and often severe negative impacts across the entire business.
- Operational Inefficiency: Teams across the organization, from sales and marketing to customer service and finance, waste considerable time and resources grappling with unreliable data. This can lead to duplicated efforts, such as two sales representatives unknowingly contacting the same prospect or customer, leading to confusion and wasted resources. Internally, a cluttered database filled with erroneous entries makes it difficult for employees to find accurate information quickly, slowing down processes and increasing frustration. Furthermore, storing redundant data consumes unnecessary storage capacity, leading to increased infrastructure costs.
- Compromised Decision-Making: Strategic business decisions increasingly rely on data analytics. However, if the underlying data is flawed, the resulting reports and insights will be inaccurate and misleading. Decisions based on such data can lead to misguided strategies, misallocation of resources, and missed market opportunities. Over time, the persistence of poor data quality erodes trust in the data itself, and consequently, in the analytical systems designed to use it. Marketers and other stakeholders may become discouraged from using data for insights if they perceive it as unreliable. This reluctance to engage with data can stifle innovation and prevent the organization from becoming truly data-driven, thereby negating significant investments in analytics platforms and personnel.
- Negative Customer Experience: Customers are directly impacted by poor data quality. Inconsistent or duplicated records can lead to unprofessional and frustrating interactions. For example, a customer might receive the same marketing email multiple times, be addressed by an incorrect name variant, or have their preferences ignored because their information is fragmented across several records. Such experiences can make a company appear disorganized and uncaring, significantly harming brand perception and eroding customer loyalty. In an era where personalized experiences are highly valued, inaccurate data makes effective personalization impossible, potentially leading customers to competitors who manage their information more effectively.
- Financial Detriment: The financial costs associated with poor customer data quality are substantial. Wasted marketing spend on duplicate communications or targeting the wrong audience is a direct loss. Missed sales opportunities arise when sales teams pursue incorrect or incomplete leads, or when customer service cannot resolve issues efficiently due to conflicting information. Industry analysts have quantified these costs: Gartner, for instance, reported that poor data quality costs organizations an average of $12.9 million annually, while IBM estimated that bad data costs the U.S. economy around $3.1 trillion per year. These figures underscore that data quality is a bottom-line issue.
- Compliance Risks: Many industries are subject to data privacy and protection regulations, such as the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA). These regulations often include mandates for data accuracy and the ability to provide customers with a complete view of their data upon request. Inconsistent and duplicated data makes it difficult to comply with these requirements, potentially leading to significant fines and reputational damage.
The following table summarizes these detrimental impacts:
Table: Detrimental Impacts of Poor Customer Data Quality
| Impact Area | Specific Negative Impact | Business Consequence |
|---|---|---|
| Financial | Wasted Marketing Spend, Increased Operational Costs (Storage, Labor), Missed Sales Opportunities | Lower ROI, Reduced Profitability, Inefficient Resource Allocation |
| Operational | Reduced Employee Productivity, Duplicated Efforts, Cluttered Databases, Inefficient Processes | Slower Execution, Increased Errors, Higher Operational Friction |
| Customer Relations | Inconsistent Communications, Poor Personalization, Negative Service Interactions | Customer Dissatisfaction, Churn, Damaged Brand Reputation, Loss of Trust |
| Strategic Decision-Making | Unreliable Reporting & Analytics, Flawed Business Strategies, Eroded Trust in Data | Misguided Investments, Missed Market Opportunities, Reduced Agility |
| Compliance | Difficulty Meeting Regulatory Requirements (e.g., GDPR, CCPA), Inaccurate Reporting to Authorities | Legal Penalties, Fines, Reputational Damage, Loss of Licenses |

Addressing data inconsistency and duplication is therefore not just about cleaning up records; it is about safeguarding the operational efficiency, strategic capability, customer relationships, financial health, and legal standing of the organization.
3. Uncovering the Root Causes
To effectively address inconsistent and duplicated customer data, it is crucial to understand the underlying factors that contribute to its proliferation. These causes are often interconnected and can be grouped into human and process-related factors, system-level deficiencies, and broader organizational and governance gaps.
3.1. Human and Process-Related Factors
Human interaction with data and the processes governing these interactions are significant sources of data quality issues. In fact, inefficient data entry processes and lack of standardization often open the door to recurring problems.
- Manual Data Entry Errors: This remains one of the most common culprits. Simple human errors such as typos (e.g., entering "john.doe@gmail.cmo" instead of "john.doe@gmail.com" ), misspellings, formatting mistakes, and transposition errors can introduce inaccuracies at the point of data creation. Accidental duplicate entries also occur when, for example, a customer's information is entered twice due to oversight or during a busy period. Over time, these seemingly minor errors accumulate, leading to a substantial degradation of data quality.
- Inconsistent Data Entry Practices: When organizations lack standardized procedures for data entry, employees may record the same information in varied ways. This includes using different abbreviations (e.g., "St," "Str," or "Street" for street designations ), inconsistent capitalization, or varying formats for dates, phone numbers, and names. Such inconsistencies make it difficult to search, aggregate, and analyze data effectively. This problem is often exacerbated by a lack of clear, documented guidelines and standards for data entry across all departments and touchpoints. If there are no established rules for how data should be captured, individuals will inevitably develop their own idiosyncratic methods, leading to systemic inconsistency.
- Lack of Training and Awareness: Employees involved in data entry or management may not fully understand the critical importance of data accuracy or be aware of the correct procedures and best practices. Without adequate training on data standards, the potential impact of errors, and how to use data entry systems correctly, the likelihood of mistakes increases significantly.
These human and process factors often point to deeper issues. For instance, a high rate of manual data entry errors might not solely be due to carelessness but could be a symptom of poorly designed data entry interfaces, unrealistic time pressures, or, more fundamentally, a lack of established data entry standards and an overarching data governance framework. Addressing only the superficial errors without tackling these underlying process and standards deficiencies will likely result in recurring problems.
3.2. System-Level Deficiencies
The design, integration, and configuration of IT systems play a critical role in maintaining data quality. Deficiencies in these areas can systematically generate and perpetuate inconsistencies and duplications. For organizations leveraging automation or integrating AI into their data operations, it's vital to understand how AI-enabled software development can both accelerate processes and introduce new complexities in data consistency and integration.
- Disparate or Poorly Integrated Systems (Data Silos): Many organizations use multiple software systems (e.g., CRM, ERP, marketing automation, e-commerce platforms) that store customer data. If these systems are not effectively integrated, they become data silos. The same customer data might be entered or updated in one system but not synchronized with others. This lack of communication leads to discrepancies, where different systems hold conflicting versions of customer information, and can result in the same data being entered into multiple systems without recognizing existing entries as duplicates.
- Data Migration Problems: Migrating data from legacy systems to new platforms, or consolidating data during mergers and acquisitions, is a complex process fraught with risk. Errors such as improper data mapping (incorrectly matching fields between old and new systems), flawed data transformation logic, or incomplete data transfer can introduce widespread inconsistencies and duplications into the target systems.
- Lack of Unique Identifiers / Incorrect Unique Columns: A fundamental requirement for avoiding duplication and ensuring data consistency is the ability to uniquely identify each customer. If there is no globally unique identifier (e.g., a master
Customer_ID) consistently used across all systems, it becomes extremely difficult for systems to recognize that multiple records pertain to the same entity. This is a common cause of duplication. Furthermore, even when systems attempt to use unique keys for operations like "upsert" (update existing record or insert new one), choosing an incorrect field as the unique identifier can lead to massive data duplication. For example, using a transient field likeLogin Timeinstead of a stableCustomer_IDwill result in the system treating most incoming records as new, thereby creating duplicates instead of updating existing ones. - Source Data Anomalies: Sometimes, data quality issues originate in the source systems themselves, even before any integration or processing occurs. The source data might already contain duplicate records (e.g., a customer registering multiple times with different email addresses or phone numbers) or inherent inconsistencies. When this flawed data is ingested into other systems, the problems are propagated and often amplified.
- Incorrect System Configurations: Certain system configurations can inadvertently generate duplicate data. For instance, an incorrect snapshotting policy for data synchronization, such as setting a daily sync to pull the last seven days of data, will result in each day's data being replicated sevenfold over a week. Similarly, using an "insert" write mode for data storage destinations instead of an "upsert" mode (which updates existing records and inserts new ones) will lead to duplicates if records for the same entity are processed multiple times.
- Legacy Systems: Older, legacy systems may not adhere to modern data management practices or be easily compatible with newer technologies. When data is transferred or integrated between legacy and modern systems, discrepancies can arise due to data transformation errors, differences in data type handling, or loss of data fidelity, contributing to inconsistencies.
System-level issues, particularly those related to poor integration and the mismanagement of unique identifiers, can act as "force multipliers" for bad data. While a manual error might create a single duplicate, a misconfigured system process or a flawed integration can generate thousands or even millions of duplicate or inconsistent records automatically and rapidly. This underscores the critical importance of auditing and rectifying these systemic flaws.
3.3. Organizational and Governance Gaps
Beyond individual actions and system configurations, broader organizational factors and the absence of effective data governance create an environment where poor data quality can thrive. These governance gaps are also a core reason why many low-code platforms eventually face limitations—their promise of rapid deployment can be undermined by a lack of disciplined data standards and oversight.
- Lack of Data Standards: The absence of clearly defined, organization-wide standards for data elements (e.g., definitions, formats, permissible values, naming conventions) means that different departments or individuals may interpret and record data differently. This inevitably leads to variations and inconsistencies that hinder data integration and analysis.
- Inadequate Data Governance: Data governance encompasses the policies, procedures, roles, responsibilities, and controls for managing an organization's data assets. A lack of robust data governance means there is no systematic oversight of data quality, no clear accountability for maintaining data integrity, and no established processes for validating, cleansing, or monitoring data. In such an environment, inconsistencies and duplications can persist undetected and unaddressed, and even well-intentioned efforts to improve data quality in one area may be undermined by a lack of coordination or conflicting practices elsewhere. This absence of a guiding framework is not merely a passive deficiency but actively enables data chaos, as there are no mechanisms to enforce standards or correct deviations.
- Incomplete Updates: Even if data is initially correct, failure to propagate updates across all relevant systems in a timely and synchronized manner leads to inconsistencies. For example, a customer might update their address through a web portal, but if this change is not reflected in the billing system and the marketing database, different parts of the organization will operate with conflicting information.
- Organizational Changes: Mergers, acquisitions, reorganizations, or even significant shifts in roles and responsibilities can disrupt established data handling practices. If not managed carefully with a focus on data continuity and consistency, such changes can lead to confusion, breakdowns in data workflows, and the introduction of new data quality problems.
The following table categorizes these common causes:
Table: Common Causes of Customer Data Inconsistency and Duplication
| Cause Category | Specific Cause | Description/Example |
|---|---|---|
| Human/Process-Related | Manual Data Entry Errors | Typos, misspellings, transposition errors during input (e.g., "Jhon" instead of "John"). |
| Inconsistent Data Entry Practices | Using varied abbreviations (e.g., "Rd." vs. "Road"), formats, or capitalizations without a standard. | |
| Lack of Training and Awareness | Employees unaware of data standards, importance of accuracy, or correct system usage. | |
| System-Level Deficiencies | Disparate or Poorly Integrated Systems (Data Silos) | CRM, ERP, and marketing platforms not syncing customer updates, leading to conflicting data. |
| Data Migration Problems | Errors in mapping or transforming data when moving to new systems, creating inconsistencies. | |
| Lack of Unique Identifiers / Incorrect Unique Columns | No single customer ID leads to multiple records; using Login Time instead of Customer_ID for upserts creates duplicates. | |
| Source Data Anomalies | Duplicates or errors already present in original data sources (e.g., customer self-registers twice with different emails ). | |
| Incorrect System Configurations | Daily full data reload instead of incremental updates; incorrect snapshotting policies leading to data replication. | |
| Legacy Systems | Older systems with incompatible data formats leading to transformation errors when interfacing with modern systems. | |
| Organizational/Governance Gaps | Lack of Data Standards | No defined organization-wide format for phone numbers, addresses, or industry codes. |
| Inadequate Data Governance | No clear ownership, policies, or processes for ensuring and monitoring data quality; issues persist undetected. | |
| Incomplete Updates | Changes made in one system (e.g., new address) not propagated to all other relevant systems. | |
| Organizational Changes | Mergers or restructurings disrupting data management workflows without proper data integration planning. |
Understanding these root causes is essential for developing targeted and effective solutions. Simply treating the symptoms, such as correcting individual errors, without addressing the underlying systemic and governance issues will result in a perpetual cycle of data degradation.
4. A Strategic Framework for Resolution and Prevention
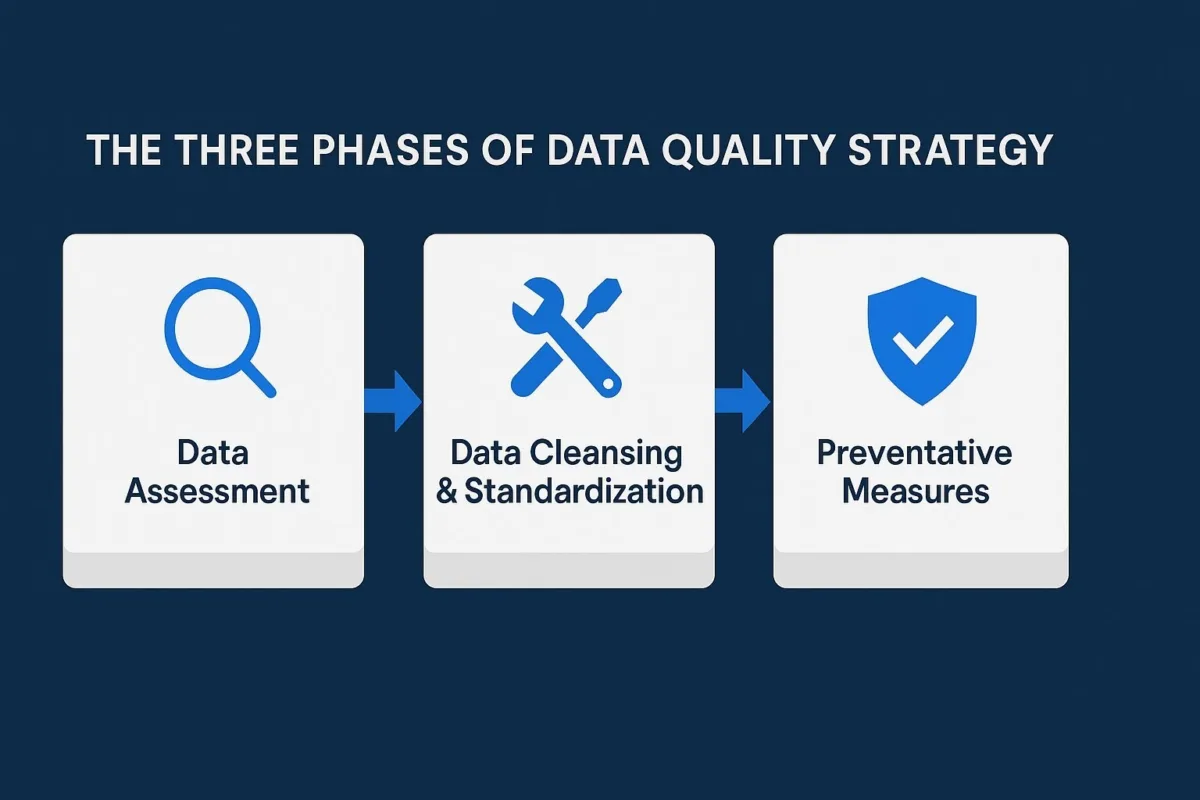
Addressing the pervasive issues of customer data inconsistency and duplication requires a structured, phased approach. This framework encompasses an initial comprehensive assessment, followed by intensive data cleansing and standardization, and culminating in the implementation of robust preventative measures to ensure sustained data integrity.
4.1. Phase 1: Comprehensive Data Quality Assessment
Before any corrective action can be effectively undertaken, a thorough understanding of the current state of customer data is paramount. Attempting to cleanse data without a clear picture of the types, extent, and locations of errors is akin to navigating without a map - inefficient and likely to miss critical issues.
- Profiling and Auditing Existing Customer Data: Data profiling is the critical first step. It involves systematically examining the data within customer databases and other relevant systems to understand its structure, content, quality, and the relationships between different data elements. This process typically includes:
- Attribute Analysis: Identifying all data fields (attributes) related to customers (e.g., name, address components, contact details, account information) and understanding their definitions, data types, and intended use.
- Statistical Analysis: Evaluating the data within each attribute for characteristics such as completeness (e.g., percentage of null or missing values), uniqueness (e.g., frequency of distinct values), distribution (e.g., range and common values), and conformity to expected patterns. For instance, analyzing the
email_addressfield to identify malformed entries or thepostal_codefield for non-standard formats. - Tools and techniques such as automated data profiling software, querying databases for specific patterns, data sampling, and developing data quality scorecards can be employed to gain these insights. The objective is to create a baseline understanding of data quality metrics, such as the percentage of incomplete customer records, the estimated number and types of duplicate entries, and the prevalence of formatting inconsistencies.
- Identifying Hotspots of Inconsistency and Duplication: Not all data quality issues carry the same business impact. The assessment phase should aim to identify "hotspots" - specific datasets, systems, or data attributes where inconsistencies and duplications are most severe or where poor data quality has the most detrimental effect on critical business processes (e.g., key account management, billing accuracy, high-volume marketing campaigns). This prioritization is crucial, especially in large organizations with vast amounts of customer data, as attempting to address all issues simultaneously can be overwhelming and inefficient. Focusing on high-impact areas allows for targeted interventions that can deliver more immediate and visible improvements, thereby building momentum and support for the broader data quality initiative.
A thorough assessment provides the necessary foundation for informed decision-making in the subsequent phases. It quantifies the problem, pinpoints specific areas needing attention, and helps in selecting the most appropriate cleansing and prevention strategies.
4.2. Phase 2: Intensive Data Cleansing and Standardization
Once the data quality assessment is complete and problem areas are identified, the next phase involves the intensive work of correcting existing errors, standardizing data formats, and eliminating duplications. This phase aims to remediate the historical data quality debt.
- Core Principles:
- Data Cleaning: This involves the direct correction or removal of the inaccurate, incomplete, or inconsistent parts of the data. It can include fixing typographical errors, filling in missing values where appropriate and possible (data imputation), and removing records that are clearly erroneous or irrelevant.
- Data Standardization: This focuses on transforming data into a consistent, uniform format according to predefined rules and standards. This ensures that the same type of information is represented in the same way across all records, making data easier to compare, aggregate, and use.
- Techniques for Data Parsing, Validation, and Correction: A variety of techniques are employed to achieve clean and standardized data:
- Data Parsing: This involves breaking down complex or composite data fields into their individual, meaningful components, which are then stored in separate, standardized fields. For example, a single address line like "1600 Pennsylvania Avenue NW, Washington, DC 20500" would be parsed into distinct elements such as House Number (1600), Street Name (Pennsylvania Avenue), Directional (NW), City (Washington), State (DC), and Postal Code (20500). Similarly, a full name field might be parsed into First Name, Middle Name, Last Name, and Suffix.
- Data Validation: This is the process of checking data against a set of predefined rules, constraints, or reference data to ensure its accuracy, integrity, and conformity. Common validation checks for customer data include:
- Format Checks: Ensuring data adheres to expected patterns (e.g., email addresses must contain an "@" symbol and a valid domain structure; phone numbers must match a specific national or international format).
- Completeness Checks: Verifying that all mandatory fields contain data (e.g., a primary contact number or email address for active customers).
- Data Type Checks: Confirming that data in a field matches its defined data type (e.g., a
customer_agefield should contain only numerical values). - Range Checks: Ensuring numerical data falls within an acceptable range (e.g., age between 18 and 120).
- Referential Integrity/Table Lookups: Validating values against an authoritative list or reference table (e.g., ensuring a
state_codeexists in a master list of valid state codes, or acountry_codeis valid).
- Data Correction/Cleansing: Based on the outcomes of parsing and validation, errors are corrected. This can involve fixing typos and misspellings, replacing invalid characters (e.g., non-printable characters in names or addresses), standardizing abbreviations (e.g., consistently using "St." for "Street," "Ave." for "Avenue," or "NY" for "New York" ), and ensuring consistent capitalization. Missing values might be filled through data imputation techniques, which use statistical methods or logical rules to infer probable values, though this must be done cautiously to avoid introducing new errors.
- Effective Deduplication, Matching, and Merging Strategies: Addressing duplicate customer records is a cornerstone of this phase.
- Identification of Duplicates:
- Automated Deduplication Tools: Most modern CRM systems and specialized data quality tools offer functionalities to identify potential duplicates. These tools often employ sophisticated data matching algorithms.
- Matching Techniques: For non-exact duplicates (partial duplicates), advanced techniques like fuzzy matching are essential. Fuzzy matching uses algorithms to identify records that are highly similar but not identical, accounting for variations in spelling, abbreviations, word order, or missing components. For example, it could identify "John Smith, 123 Main St" and "Jon Smyth, 123 Main Street" as probable duplicates.
- Review and Resolution:
- Manual Review: While automation is crucial for efficiency, a manual review process is often necessary for records flagged as potential duplicates where the automated system has low confidence, or where the business rules for merging are complex.
- Merging/Consolidation: Once duplicates are confirmed, the information from the multiple records needs to be consolidated into a single, accurate "golden record." This involves defining rules for how to merge the data - for instance, which record's address to keep if they differ, or how to combine multiple phone numbers or email addresses into the primary record. Conditional rules can be established to intelligently assess attributes from duplicate records and select the most complete, accurate, or recent information for the surviving record.
- Identification of Duplicates:
4.3. Phase 3: Implementing Preventative Measures for Sustained Data Integrity
While intensive cleansing addresses past data quality issues, it is equally, if not more, critical to implement measures that prevent new inconsistencies and duplications from arising. Without robust preventative strategies, any gains from the cleansing phase will be short-lived, and the organization will find itself in a continuous, costly cycle of reactive data cleaning. Leveraging AI-powered automation and intelligent validation at the point of entry can dramatically reduce the root causes of recurring data quality problems.
- Establish Data Entry Standards and Automation: The point of data entry is the first line of defense against poor data quality.
- Clear Data Entry Guidelines: Develop and disseminate clear, unambiguous guidelines and standard operating procedures for all staff involved in creating or updating customer data. These guidelines should cover formatting rules, required fields, use of abbreviations, and other data capture conventions.
- System-Enforced Standards:
- Mandatory Fields: Configure systems to require completion of critical data fields (e.g., primary contact information, unique customer identifiers) before a new record can be saved.
- Drop-Down Menus & Picklists: For fields where values should come from a predefined set (e.g., country codes, customer types, industry classifications), use drop-down menus or picklists instead of free-text entry. This ensures consistency and reduces typographical errors.
- Input Masks and Validation Rules: Implement real-time validation rules at the point of entry to check data formats (e.g., for email addresses, phone numbers, postal codes) and alert users to errors immediately.
- Automation of Data Entry: Where feasible, automate data capture processes to minimize manual intervention and associated human error. This could involve integrating web forms directly with CRM systems, using OCR for scanned documents, or leveraging third-party services for data population or verification.
- Ongoing Monitoring, Maintenance, and Continuous Improvement: Data quality is not a static state; it requires ongoing attention and effort.
- Regular Data Audits: Schedule and conduct regular data audits (e.g., quarterly or bi-annually) to proactively identify and address any new data quality issues that may have emerged.
- Automated Monitoring and Cleanup Processes: Implement tools and scripts that continuously monitor data quality against defined metrics and rules. Many CRM and data quality platforms allow for the automation of routine cleanup tasks, such as identifying potential new duplicates or flagging records with outdated information.
- Data Quality Metrics and Reporting: Establish key performance indicators (KPIs) for data quality, such as duplicate rate, data completeness score, data accuracy rate, and email bounce rates. Track these metrics over time and use dashboards to provide visibility into data health.
- Feedback Loops and Continuous Improvement: Foster a culture where data quality is a shared responsibility. Establish processes for users to report data errors they encounter and ensure these issues are addressed promptly. Regularly review data quality processes and standards, and adapt them based on performance, changing business needs, and user feedback.
The strategic prioritization inherent in identifying "hotspots" during the assessment phase is critical for managing these often large-scale data quality projects. Attempting to "boil the ocean" by fixing everything at once is typically impractical and can lead to resource drain and slow progress, as cautioned by experts. A focused approach on areas with the highest business impact allows for quicker wins, demonstrating the value of the initiative and building support for sustained effort. Ultimately, the long-term success of any data quality initiative hinges more on the robustness of its preventative measures (Phase 3) than on the initial cleanup (Phase 2).
The following table provides a practical guide to key techniques involved in cleansing and standardizing customer data:
Table: Key Data Cleansing and Standardization Techniques for Customer Data
| Technique | Description | Application Example for Customer Data |
|---|---|---|
| Data Profiling | Analyzing data to understand its structure, content, quality, and identify anomalies. | Analyzing customer address fields for completeness (e.g., % missing ZIP codes) and format consistency (e.g., variations in state abbreviations). |
| Data Parsing | Breaking down complex data fields into smaller, standardized components. | Separating 'John Doe Jr., 123 Main St Apt 4B, Anytown, NY, 10001' into distinct fields: First Name (John), Last Name (Doe), Suffix (Jr.), Street Number (123), Street Name (Main St), Apt Number (4B), City (Anytown), State (NY), Zip (10001). |
| Data Validation | Checking data against predefined rules or standards to ensure correctness and consistency. | Verifying that email addresses follow a valid format (e.g., 'user@domain.com'). Checking if phone numbers conform to a national standard. Ensuring date_of_birth is a valid date and falls within a logical range. |
| Data Standardization | Converting data to a common format and aligning it with predefined standards. | Converting all state entries to a 2-letter ISO abbreviation (e.g., 'New York', 'N.Y.', 'NYork' to 'NY'). Standardizing street suffixes (e.g., 'Street', 'St', 'Str.' to 'ST'). Ensuring consistent capitalization for names and addresses. |
| Data Matching | Identifying records that refer to the same entity, even with variations in data (often using fuzzy logic). | Using fuzzy matching algorithms to identify 'John Smith' at '123 Main St' and 'Jon Smyth' at '123 Main Street' with a similar phone number as potential duplicates. |
| Deduplication | The process of identifying and then removing or merging duplicate records. | Systematically reviewing potential duplicates flagged by matching algorithms and either deleting redundant entries or initiating a merge process. |
| Data Merging | Consolidating information from two or more duplicate records into a single, authoritative 'golden record'. | Combining contact details, purchase history, and preferences from three duplicate records for "Catherine Jones" into one comprehensive master profile, resolving any conflicting data points based on predefined survivorship rules. |
| Data Enrichment | Appending missing information or enhancing existing data with data from external, authoritative sources. | Using third-party services (e.g., Clearbit, ZoomInfo, Melissa Data ) to validate and correct customer addresses, append missing phone numbers or email addresses, or add demographic or firmographic data to customer profiles. |
By systematically applying these phases and techniques, organizations can significantly improve the quality of their existing customer data and lay the groundwork for maintaining high levels of data integrity moving forward.
5. Building a Resilient Data Quality Ecosystem
Fixing existing data problems is only part of the solution. To achieve sustainable data integrity, organizations must build a resilient data quality ecosystem. This ecosystem is founded on three critical pillars: robust Master Data Management (MDM), comprehensive Data Governance with clear quality rules and dedicated stewardship, and the strategic leverage of appropriate technology. These components are not isolated solutions but are highly interconnected, each reinforcing the others to create an environment where high-quality customer data is the norm, not the exception.
5.1. The Role of Master Data Management (MDM) in Creating a Single Source of Truth
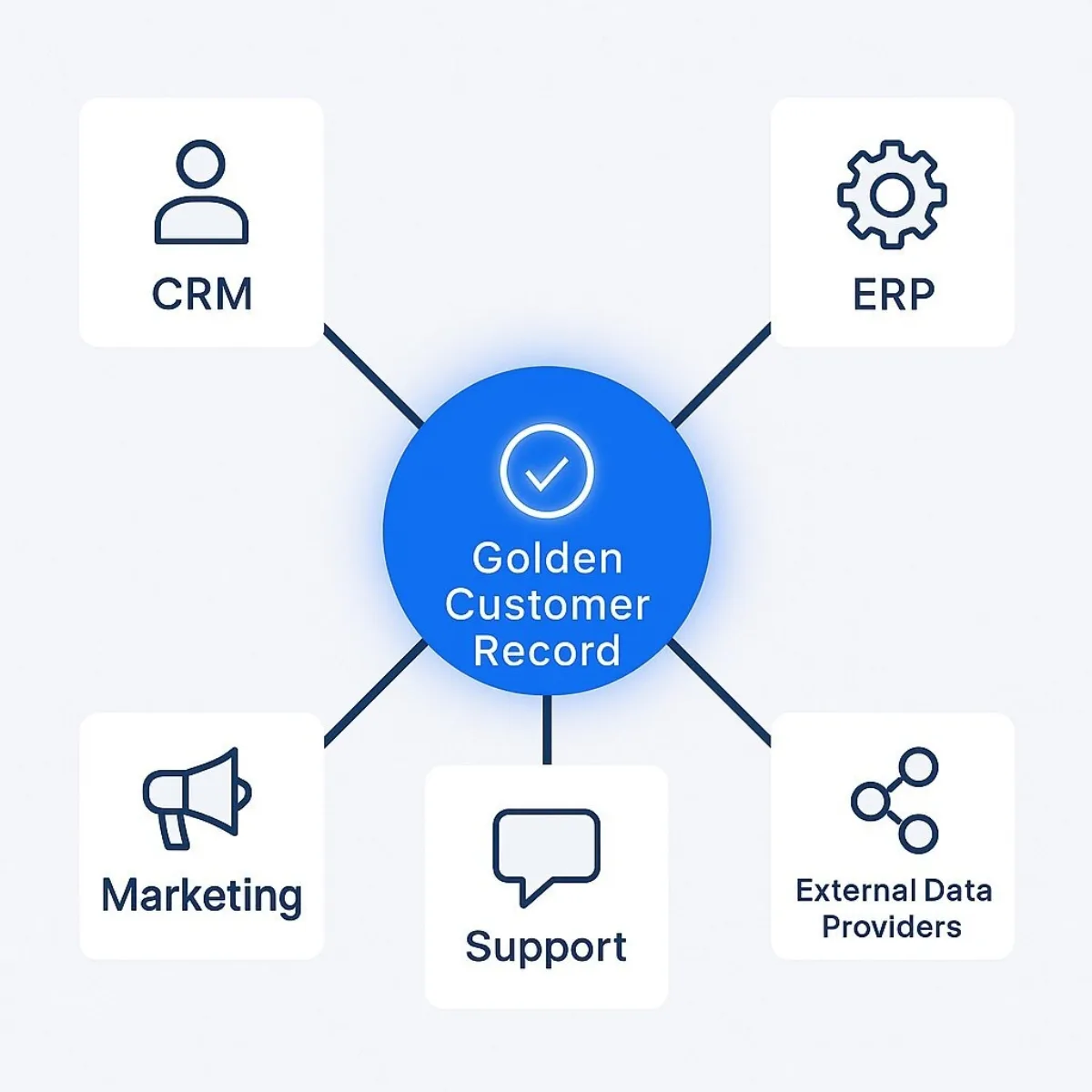
Master Data Management (MDM) is a discipline, supported by technology and processes, aimed at creating and maintaining a unified, accurate, consistent, and comprehensive view of an organization's most critical data assets - its master data. For customer data, MDM strives to establish a "single source of truth" or a "golden record" for each unique customer.
This is achieved by integrating customer data from various internal systems (CRM, ERP, billing, etc.) and potentially external sources (third-party data providers) into a central MDM hub. Within this hub, data is cleansed, standardized, deduplicated, and enriched to create the most accurate and complete profile for each customer. This master record then serves as the authoritative source, which can be synchronized back to operational systems or used directly for analytics and reporting.
The benefits of implementing MDM for customer data are significant:
- Improved Operational Efficiencies: With a single, reliable view of each customer, departments can operate more effectively, reducing wasted effort caused by conflicting or incomplete information.
- Increased Confidence in Data: MDM fosters trust in customer data across the organization, leading to more reliable analytics and better-informed strategic decisions.
- Resource Savings: By centralizing data management and automating quality processes, MDM can reduce the costs associated with manual data reconciliation and error correction.
- Enhanced Customer Experiences: Accurate and comprehensive customer profiles enable more effective personalization, targeted marketing, and improved customer service interactions.
Key components that typically form an MDM initiative include robust data governance to define policies, stringent data quality processes to maintain the integrity of master records, data integration capabilities to consolidate data from disparate sources, data security measures to protect sensitive information, dedicated data stewardship to oversee the master data, and analytical tools to derive insights from it. The successful implementation of MDM transforms customer data from a fragmented liability into a cohesive strategic asset.
5.2. Establishing Robust Data Governance, Quality Rules, and Stewardship
While MDM provides a framework for managing master data, it relies heavily on strong data governance to define the rules of engagement and ensure ongoing quality. Organizations seeking to build a strategic advantage through custom software and data must treat governance, stewardship, and quality as core pillars rather than afterthoughts.
- Data Governance: Data governance establishes the overall strategy, policies, standards, processes, and controls for managing and using an organization's data assets effectively and securely. For customer data, this means setting clear, enterprise-wide guidelines for data creation, maintenance, usage, and retirement. This includes defining data formats, naming conventions, validation checks, access controls, and privacy requirements. A well-defined governance framework clarifies roles and responsibilities, ensuring accountability for data quality. It's important to understand the relationship: data governance provides the foundational "rulebook," data stewardship is responsible for the "execution" of these rules, and data ownership ensures "accountability" for specific data domains. Without this overarching governance, even sophisticated MDM systems or data quality tools will struggle to maintain long-term data integrity, as there would be no consistent enforcement of standards or processes for managing data quality proactively.
Data Quality Rules: Data quality rules are specific, measurable, and enforceable criteria that data must meet to be considered fit for purpose. These rules operationalize data governance policies by defining the parameters and thresholds for acceptable data quality. They can be implemented to prevent low-quality data from entering systems (e.g., through input validation), to flag existing data that violates standards for review and remediation, or to guide MDM tools in standardizing and consolidating master data. These rules represent a crucial shift from purely reactive data cleaning to proactive data quality assurance, defining what "good" looks like before data is created or used in critical processes. This preventative stance is far more efficient and less costly than continually fixing problems after they arise.
Data quality rules typically address several dimensions of data quality, including:
- Accuracy: Ensuring data correctly reflects the real-world entity it describes. Example Rule: A customer's postal code must be valid for the entered city and state.
- Completeness: Ensuring all required data elements are present. Example Rule: The
email_addressfield must not be null if the customer has opted into electronic communications. - Consistency: Ensuring data is uniform and free from contradictions across different records or systems. Example Rule: If a customer's
account_statusis 'Inactive,' theirlast_transaction_datecannot be more recent than the inactivation date. - Uniqueness: Ensuring that records or attributes that should be unique are indeed unique, preventing unwarranted duplication. Example Rule: The combination of
customer_email_addressandcustomer_date_of_birthmust be unique across all customer records. - Timeliness/Freshness: Ensuring data is sufficiently up-to-date for its intended use. Example Rule: Customer contact preferences must be reviewed or confirmed at least every 24 months.
- Validity/Conformity: Ensuring data adheres to specified formats or defined business rules. Example Rule: All phone numbers must be stored in the E.164 international format.
- Data Stewardship: Data stewards are individuals or teams assigned responsibility for the day-to-day management, oversight, and care of specific data assets (e.g., the "Customer" data domain). They are the "boots on the ground" who implement and enforce data governance policies and ensure data quality standards are met. Key responsibilities of data stewards include:
- Monitoring data quality within their domain.
- Investigating and resolving data issues.
- Ensuring compliance with data policies and regulations.
- Facilitating appropriate data access.
- Maintaining data definitions and other metadata.
- Acting as subject matter experts for their assigned data. The presence of dedicated data stewards ensures that there is active ownership and accountability for maintaining the quality and integrity of customer data over its entire lifecycle.
The following table outlines core components of an effective data governance framework tailored for customer data:
Table: Core Components of an Effective Data Governance Framework for Customer Data
| Governance Component | Description | Key Considerations for Customer Data |
|---|---|---|
| Data Quality Policies | Formal, documented statements outlining the organization's commitment to data quality and the principles guiding data management. | Policies specific to the handling of Personally Identifiable Information (PII), data accuracy mandates, and data retention rules for customer records. |
| Data Standards | Defined specifications for data elements, including formats, naming conventions, valid values, and definitions. | Standards for customer name structure, address components (street, city, state, postal code), phone number formats (e.g., E.164), email address syntax, and classification codes (e.g., customer segments, industry). |
| Roles & Responsibilities | Clearly defined roles such as Data Owners, Data Stewards, Data Custodians, and their respective accountabilities for data assets. | Clearly defined Data Owner for the "Customer" master data domain; designated Data Stewards for key customer data attributes or systems (e.g., CRM steward, billing system steward). |
| Data Quality Processes | Established procedures for data validation, monitoring, issue identification, remediation, and prevention. | Documented process for validating new customer records at point of entry; regular (e.g., monthly) data quality monitoring reports; defined workflow for investigating and correcting identified data errors. |
| Data Quality Metrics & Reporting | Key Performance Indicators (KPIs) and dashboards to measure, track, and report on the state of data quality. | KPIs such as percentage of duplicate customer records, percentage of complete customer profiles (e.g., all mandatory fields filled), address accuracy rate, email validation rate. Dashboards providing real-time views of these metrics. |
| Supporting Technology & Tools | Software and platforms used to enable data governance, data quality management, and MDM. | Data quality tools integrated with CRM and other customer-facing systems; MDM platform (if applicable); data catalog for metadata management; workflow tools for issue resolution. |
The following table provides illustrative data quality rules:
Table: Illustrative Data Quality Rules for Customer Data
| Data Quality Dimension | Rule Example for Customer Data | Purpose |
|---|---|---|
| Accuracy | Customer's postal code must exist within the specified city and state, validated against a postal reference database. | Ensures correct geographical targeting, reduces mail returns, and supports accurate location-based analytics. |
| Completeness | Email address field cannot be empty for customers who have opted into electronic communication and have an 'Active' status. | Enables essential digital communication, supports marketing campaigns, and ensures compliance with communication preferences. |
| Consistency | If Account_Status is 'Closed', then Last_Activity_Date cannot be in the future or more recent than the Account_Closure_Date . | Maintains logical data integrity, prevents contradictory information, and supports accurate customer lifecycle analysis. |
| Uniqueness | No two customer records can share the same primary email address AND last name combination if both are populated. | Prevents the creation of duplicate customer profiles, ensuring a single view of the customer. |
| Timeliness/Freshness | Customer contact information (phone, email, address) must be verified or have a 'last updated' timestamp within the last 12 months for premier customers. | Ensures data is current for important outreach, reduces wasted communication efforts, and maintains relationship accuracy. |
| Validity/Conformity | Phone number must follow the E.164 standard format (e.g., +1XXXXXXXXXX). Date of Birth must be in 'YYYY-MM-DD' format. | Standardizes phone data for system compatibility and international dialing. Ensures consistent date representation for calculations and system processing. |
5.3. Leveraging Technology: Selecting and Implementing Data Quality Tools
While processes and governance are foundational, technology is a critical enabler for managing data quality at scale. Manual checks and corrections are simply unsustainable in modern data environments characterized by high volumes, velocity, and variety of data.
Organizations should invest in specialized data quality tools that can automate and streamline various aspects of the data quality lifecycle. Key capabilities to look for in such tools include:
- Data Profiling: To analyze data, discover its characteristics, and identify anomalies.
- Data Parsing and Standardization: To break down and reformat data elements into consistent structures.
- Data Cleansing: To correct errors, remove invalid characters, and handle missing values.
- Data Validation: To check data against predefined business rules and quality standards.
- Data Matching and Deduplication: To identify and manage duplicate records using deterministic and probabilistic (fuzzy) matching algorithms.
- Data Enrichment: To append missing information or verify data against external authoritative sources.
- Monitoring and Reporting: To track data quality metrics over time and provide dashboards for visibility.
- Integration Capabilities: To seamlessly connect with existing systems like CRMs, ERPs, and data warehouses.
Various types of tools can support these functions, including standalone data quality platforms (e.g., Informatica Cloud Data Quality ), data integration tools with built-in quality features (e.g., dbt ), MDM solutions , and even specialized services for tasks like address verification (e.g., AddressDoctor, SmartyStreets, Melissa Data ) or contact data enrichment (e.g., Clearbit, ZoomInfo ). The selection should be based on the organization's specific needs, existing technology landscape, and the scale of its data quality challenges. For organizations looking to make use of intelligent automation and next-generation efficiency, consider exploring enterprise automation platforms that can integrate seamlessly with your existing data stack.
It is crucial to remember that technology alone is not a silver bullet. Its effectiveness is significantly amplified or diminished by the human element. Clear roles, such as well-trained data stewards , and a pervasive data-aware culture where all employees understand their role in maintaining data quality, are essential for maximizing the return on technology investments. Without this human engagement and cultural commitment, even the most advanced tools may fail to deliver sustainable improvements.
6. Action Plan: Key Recommendations and Next Steps

Translating the strategic framework and ecosystem components into a tangible plan requires a prioritized, phased approach. This ensures that efforts are manageable, early successes can be demonstrated, and momentum is built for long-term commitment. The following action plan outlines key recommendations across immediate, medium-term, and long-term horizons. This phased strategy is crucial, as attempting to address all data quality issues simultaneously can lead to overwhelming complexity and a lack of focus.
Immediate Actions (Next 30-90 days)
The focus of the initial phase is on understanding the scope of the problem, establishing foundational governance elements, and achieving some quick wins to demonstrate value.
- Form a Cross-Functional Data Quality Task Force:
- Assemble a dedicated team comprising representatives from IT, key business units (e.g., Sales, Marketing, Customer Service who are primary users and creators of customer data), and individuals identified as potential data stewards.
- This task force will champion the data quality initiative, provide diverse perspectives, and facilitate communication and coordination across departments.
- Conduct an Initial Data Quality Assessment:
- Perform a rapid data profiling exercise on core customer data repositories (e.g., primary CRM system, main sales database) as outlined in Phase 1 of the strategic framework.
- Objective: To gain an initial understanding of the types and prevalence of inconsistencies and duplications, and to identify the most critical areas affected.
- Identify and Prioritize "Quick Win" Cleansing Initiatives:
- Based on the initial assessment, select 2-3 high-impact, relatively low-complexity areas for an initial cleansing effort. This could be deduplicating records for key accounts, standardizing addresses for a specific customer segment, or correcting critical errors in a frequently used dataset.
- Successful quick wins will build confidence and support for the broader initiative.
- Draft Foundational Data Governance Policies and Standards:
- Begin documenting core data governance policies specifically for customer data, focusing on data entry standards, basic data quality rules (e.g., for completeness and format of essential fields like email and phone), and responsibilities for data creation.
Medium-Term Actions (3-6 Months)
This phase focuses on broader cleansing efforts, formalizing governance structures, implementing enabling technology, and building organizational capability.
- Implement Comprehensive Data Cleansing and Standardization:
- Execute the data cleansing and standardization activities (as per Phase 2 of the strategic framework) for the prioritized datasets identified in the assessment phase.
- Employ techniques such as parsing, validation, standardization, matching, and merging.
- Select and Begin Implementing Data Quality Tools:
- Evaluate and select appropriate data quality software for tasks like data profiling, cleansing, deduplication, and ongoing monitoring, based on the organization's needs and budget.
- Begin the implementation and configuration of these tools, integrating them with key customer data systems.
- Formalize Data Stewardship Roles:
- Officially define the roles and responsibilities of data stewards for customer data, as discussed in the data governance section.
- Assign individuals to these roles and provide them with the necessary authority and resources.
- Develop and Deliver Initial Training Programs:
- Create and roll out training programs for all employees involved in handling customer data. This training should cover the new data standards, data entry procedures, the importance of data quality, and how to use any new data quality tools.
- Establish Initial Data Quality Monitoring and Reporting:
- Implement dashboards and reports to track the key data quality metrics (KPIs) defined earlier (e.g., duplicate rates, completeness scores).
- This will provide visibility into the effectiveness of cleansing efforts and help identify emerging issues.
Long-Term Actions (6-12+ Months)
The long-term vision is to embed data quality practices into the organizational DNA and establish a continuously improving ecosystem. As organizations grow, the complexity of customer data multiplies. To address this, consider studying custom CRM development as a strategy for sustaining high-quality, unified customer records and enabling smart integrations.
- Evaluate and Potentially Implement a Master Data Management (MDM) Solution:
- Based on the complexity of the customer data landscape, the number of source systems, and the strategic importance of a single customer view, evaluate the business case for an MDM solution.
- If justified, plan and execute the implementation of an MDM system for customer data.
- Fully Embed Data Governance Practices:
- Ensure that data governance policies and procedures are integrated into all relevant business processes and system development lifecycles.
- Regularly review and update governance policies to reflect changing business needs and regulatory requirements.
- Establish a Continuous Cycle of Data Quality Improvement:
- Move beyond project-based cleansing to a state of continuous data quality monitoring, regular auditing, and ongoing improvement initiatives.
- Refine data quality rules and processes based on performance and feedback.
- Expand Data Quality Initiatives:
- Leverage the successes and lessons learned from the customer data quality initiative to address data quality in other critical data domains within the organization (e.g., product data, supplier data).
Guidance on Fostering a Data-Aware Culture
Technical solutions and process changes alone are insufficient for achieving lasting data quality. Cultivating a data-aware culture, where every employee understands the value of accurate data and their role in maintaining it, is paramount for success. Key elements include:
- Executive Sponsorship: Secure visible and vocal support from executive leadership. When leaders champion data quality, it signals its strategic importance to the entire organization.
- Consistent Communication: Regularly communicate the objectives, progress, and benefits of the data quality initiative. Share success stories and highlight the impact of improved data on business outcomes.
- Cross-Functional Collaboration: Foster strong collaboration and open communication channels between IT teams, data governance bodies, data stewards, and business users. Data quality is a shared responsibility.
- Training and Empowerment: Provide ongoing training and resources to equip employees with the knowledge and skills to manage data effectively. Empower them to identify and report data quality issues.
- Recognition and Incentives: Acknowledge and reward individuals and teams who demonstrate good data practices and contribute to data quality improvements. This can help reinforce desired behaviors.
By following this phased action plan and actively working to build a data-conscious culture, organizations can systematically address their current customer data challenges and establish a foundation for sustained data excellence.
7. Conclusion
The presence of inconsistent and duplicated customer data represents a significant impediment to operational efficiency, strategic decision-making, customer satisfaction, and regulatory compliance. This report has detailed the common causes, ranging from human error and flawed processes to systemic deficiencies and inadequate governance. The detrimental impacts are clear, manifesting in wasted resources, compromised analytics, poor customer experiences, and direct financial losses.
However, these challenges, while substantial, are solvable. A holistic and sustained approach is required, beginning with a thorough assessment to understand the problem's scope, followed by intensive data cleansing and standardization to rectify existing issues. Critically, this must be complemented by robust preventative measures, including the establishment of clear data entry standards, the automation of validation processes, and ongoing monitoring.
The long-term solution lies in building a resilient data quality ecosystem. This ecosystem is underpinned by the principles of Master Data Management (MDM) to create a single source of truth for customer information , a comprehensive data governance framework that defines policies and assigns accountability , and the strategic deployment of appropriate data quality technologies. The establishment of data quality rules and the empowerment of data stewards are vital components of this ecosystem, shifting the organization from a reactive to a proactive stance on data integrity.
The journey to high-quality customer data is not a one-time project but a continuous commitment to improvement, vigilance, and adaptation. It requires not only technical solutions and process refinements but also a cultural shift towards data awareness and shared responsibility across the organization.
The transformative benefits of achieving and maintaining high-quality customer data are manifold. They include more accurate and reliable business intelligence leading to enhanced decision-making, improved operational efficiency through streamlined processes, superior customer experiences driven by accurate personalization and consistent interactions, increased revenue opportunities, and a stronger compliance posture. By embracing the strategies and actions outlined in this report, an organization can convert its customer data from a liability into a powerful strategic asset, paving the way for sustained growth and competitive advantage in an increasingly data-centric world.
About Baytech
At Baytech Consulting, we specialize in guiding businesses through this process, helping you build scalable, efficient, and high-performing software that evolves with your needs. Our MVP first approach helps our clients minimize upfront costs and maximize ROI. Ready to take the next step in your software development journey? Contact us today to learn how we can help you achieve your goals with a phased development approach.
About the Author

Bryan Reynolds is an accomplished technology executive with more than 25 years of experience leading innovation in the software industry. As the CEO and founder of Baytech Consulting, he has built a reputation for delivering custom software solutions that help businesses streamline operations, enhance customer experiences, and drive growth.
Bryan’s expertise spans custom software development, cloud infrastructure, artificial intelligence, and strategic business consulting, making him a trusted advisor and thought leader across a wide range of industries.